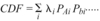Instrumentation and control
Digital I&C is safe enough
11 December 2009Claims of very low failure on demand probabilities – circa 10-9 – for digital I&C systems are not realistic, especially because other factors, such as human error and hardware, start to play a role at probabilities below 10-4. The most important common cause failures, which dwarf software errors, are listed with their probabilities. By John Bickel.
Frequent objections to the deployment of modern digital instrumentation and control (I&C) systems in nuclear safety applications such as automatic reactor trip and engineered safeguards actuation are that:
It is not possible to demonstrate that such systems are sufficiently reliable for carrying out their intended safety functions.
Methods to assess Digital I&C system reliability are incomplete because while hardware components may be analyzed using standard failure probability estimation techniques such as fault trees, no methods exist to quantify the reliability of embedded software.
Limited operating experience indicates Digital I&C systems have the potential to exhibit unpredictable failure modes not found in the older types of safety systems they are replacing.
Are these concerns completely correct? - And if so, how can one proceed with further I&C modernization efforts?
If the reliability objective of a safety related I&C system is to assure with high confidence that there will be zero failures, then obviously no system designed by human beings, digital or otherwise, can meet this objective. So what is a realistic design reliability objective?
A number of reactor designers have prepared detailed risk assessments which take credit for very low probabilities for failure to shutdown the reactor. In general, these are a combination of the probabilities of the primary reactor shutdown system failure and the failure of a diverse reactor shutdown system. By asserting a high degree of diversity one would be allowed to directly multiply the individual failure probabilities based upon their statistical independence. Regulatory bodies reviewing such analyses frequently challenge the technical bases of the individual failure probabilities. A recent example of this was the United Kingdom Health and Safety Executive [Ref. 1] which challenged the basis for the Teleperm XS Protection System having a 1x10-5 probability of failure on demand, and the diverse backup protection having a 1x10-4 probability of failure on demand. Assuming the necessary diversity of the systems, this would yield an overall failure on demand probability for the logic of ~ 10-9. But unless there is some provision for complete diversity in the switchgear breakers and control rods – this very low number will be dwarfed by the common cause failure probability of the control rods themselves which is likely on the order of 10-6 to 10-5 at best - and these numbers would be equally difficult to justify based upon experience data. Why should one be seeking a 10-9 failure on demand probability for the digital I&C logic when the common cause failure of control rods due to issues such as mechanical jamming is three or more orders of magnitude larger? What is needed are more realistic reliability design objectives for the digital I&C that can be traced back to prior experience and shown to be within the available pool of operating failure data.
To establish a realistic design objective, it is necessary to understand two things. First, how is achieving some safety objective (such as minimizing core damage frequency) sensitive to the assumed failure probability of achieving a specific safety function (such as reactor shutdown1). Second, how is the overall failure probability of achieving reactor shutdown sensitive to the failure probability of the digital I&C system. We recognize:
There are several subsystems whose failure probability contributes to the overall failure probability of achieving reactor shutdown. These include failure probabilities of: the redundant sensors (PS), the digital I&C logic (PIC), the reactor trip switchgear (PSG), and the control rods themselves (PCR). The overall failure probability of the shutdown function can be simplistically thought of as a linear sum of all of these terms:
PRT = PS + PIC + PSG + PCR.
If consideration is given to the ability of control room operators to initiate a manual shutdown via a pathway diverse from the sensors, digital logic, and switchgear, this can be reflected via an operator failure probability of: POP , and will yield an overall failure probability of shutdown function of:
PRT = (PS + PIC + PSG)*POP + PCR.
If one wishes to additionally credit a fully diverse automatic reactor shutdown system using diverse instruments and logic – this could be substituted for the probability of operator action: POP.
Given that all of these subsystems are composed of four redundant single failure tolerant trains, we would expect that the failure probabilities are pretty much dominated by common cause failure effects.
Using a standard risk assessment model of core damage frequency2 for a wide spectrum of initiating events, certain initiating events directly impact the overall probability of failing to achieve reactor shutdown. In particular, a large loss of coolant accident (LOCA) accomplishes shutdown on its own due to voiding. A loss of AC power to station auxiliaries will cause switchgear to de-energize without requiring functioning of the sensors, I&C logic, or trip switchgear – thus leaving only the possibility of mechanical jamming of control rods: PCR.
Considering a spectrum of initiating events each characterized by frequency of occurrence: ?li , the core damage frequency: CDF, can be expressed as a linear sum of accident sequences composed of an initiating event, various combinations of mitigating system (such as reactor trip) failures and successes for specific initiating events.

When the risk assessment model is fully assembled [Ref. 2], one can compute the conditional CDF values for an assumed I&C system failure on demand probability: PIC. This has been done on operating reactors using the risk assessment models for four US nuclear power plants originally designed by Combustion Engineering (CE): Arkansas 2, Waterford 3, Palo Verde 1,2,3, and San Onofre 2,3. When this is done one obtains curves similar to that shown in Figure 1. Figure 1 is based on the following assumed failure probabilities which are consistent with USNRC sponsored risk assessment models [Ref. 3,4,5,6]:
PS ~ 1.0 x 10-4
PSG ~ 1.4x10-5
POP ~ 1.0x10-2
PCR ~ 1.2x10-6

What does Figure 1 tell us [note figure also in PDF]? As the failure probability of the I&C portion of reactor shutdown function is reduced from 1/100 to 1/1,000 – the conditional core damage probability reduces monotonically as one would expect. As the failure probability decreases below ~5.0x10-4 on demand, however, there is no measurable decrease in condition core damage frequency. This is because all of the other contributors to failure on demand probability become more dominant. To make the overall failure probability on demand reduce, it would be necessary to make significant reductions in all of the other terms which sum to the total failure on demand probability. But upon looking at these terms, they are already pretty low to begin with, and if a regulator did not believe an applicant’s argument that digital I&C logic were on the order of ~10-5 why would we expect that other portions could be justified below this level?
Thus a more realistic approach is for a reliability design objective for the reactor trip system logic of: PIC ~ 5.0x10-4. This range can actually be supported by existing reactor operating experience data.
Risk assessment
Current day probabilistic risk assessments based upon fault tree and event tree models utilize existing single component failure rates and common cause failure rates based upon prior nuclear experience for pumps, valves, breakers, switches, etc. There have always been certain failure modes for which there is no actual experience and expert judgment consensus is utilized. Good examples of this include: reactor pressure vessel rupture, large double-ended pipe break loss of coolant (LOCA) accidents.
When it comes to modeling the relative failure rates of modern digital I&C systems there is also actual operating experience, which can be utilized. Ref. 2 provided one of the first comprehensive reliability databases for the first generation digital computer based protection systems (called core protection calculators) used on a number of Combustion Engineering designed reactors starting in the late 1970s. The data reported in Ref. 2 was based upon 1.27 x106 hours of reactor operating experience from 1984 through 2006 on a common digital I&C design deployed on seven nuclear power plants. Recent work to update and expand this date base through calendar year 2008 and going back to 1979 is shown in Tables 1 and 2. The operating experience data is based upon review of 208 separate licensee event reports (LERs), covering 76 automatic reactor trips, 40 events involving common cause failure, and a considerable number of individual component failures.
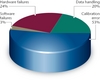
Table 1 shows the relative frequency of observed common cause failure rates based upon a review of this reactor operating experience. Table 2 shows the observed failure rates for the major digital I&C subsystems. Table 1 failure rates are summarised in Figure 2. The first three general categories in Figure 2 can be found in any I&C system (modern Digital I&C, or older analogue/relay based I&C) and include issues such as: problems cross calibrating excore neutron power signals against secondary calorimetric DT power3, drift in resistance temperature detector (RTD) response times, and common cause failures in the generation of setpoints (analysis errors and inserting older out of date setpoints or numerical constants). Each of the first three categories involves common cause failure events that have happened repeatedly over the last thirty years.

The category involving latent software error involves a single observed event [Ref. 7] in which a software update was provided to address single sensor failure. In the original design a single sensor failure when detected would cause an alarm that would be dealt with by placing the effected channel in a tripped state until corrected. With the addition of backup sensors it was desirable to make use of a secondary sensor if the primary sensor was determined to be out of tolerance. The software was modified to switch over to the backup sensor if the primary sensor failed. If the secondary sensor failed, the software was designed to use the last good value. This created a situation where if there were multiple failed sensors, the software would continue to use the last good value indefinitely. The software error was not detected in software release testing – but was identified in a software review after the software had been running for >2,700 hours. This latent failure would require common cause failure of multiple input sensors and an event which required the functioning of this portion of the reactor trip system. Neither of these required conditions occurred, so there was no impact on plant safety.
One objective of a probabilistic risk assessment is to develop estimates of failure on demand probability of various systems and components and show how these relate to overall core damage frequency and frequency of large releases. The standard approach for periodically-tested components is to base failure-on-demand probability on a time averaged unavailability model where: P ~ ½lu, where:
• P is the failure on demand probability
• l is the failure rate per hour
• u is the average time between tests
This repairable systems reliability (or Markov-type) approach works well for hardware components and for many common cause failure events which can result in systems failure, be detected as failed via periodic tests or other diagnostics, and then be restored to a fully-operable state within some average time period. Given that available experience indicates that common cause calibration, hardware, and data handling errors dominate observed software related failures by a factor of greater than 30:1, I conclude that estimates of overall failure on demand probabilities of digital I&C systems based primarily on hardware and personnel common cause failure statistics are reasonable.
Counting bugs
It has been pointed out by the US NRC’s Advisory Committee on Reactor Safeguards [Ref. 7] the repairable systems reliability approach (or Markov type approach) is not appropriate or applicable for quantification of latent software errors. Such failures are embedded in software but typically require a triggering event – which is some combination of unanticipated inputs which the software then responds to - exactly as it is programmed to. Obviously the objective of a quality software design and qualification testing program is to assure that functional requirements are properly defined; that software implements the functional requirements; that combinations of ‘un-physical inputs’ are properly controlled.
Despite these efforts, some low probability, which we can denote as ‘e’ exists that some undetected latent ‘bug’ may exist in the software implementation – and when combined with a triggering event the system will fail. Predicting exactly what e is based upon reviewing a digital I&C system design and its embedded software is more judgmental than quantitative.
Clearly implementation of a very simple functional requirement such as: read-in an input, scale (or adjust) it, compare it to a setpoint constant, and decide whether or not to generate a trip signal – is an extremely simple functional requirement with few lines of required software coding and is easy to verify. The complexity of the CE designed core protection calculator system from the 1970s was essentially an online computation of static and dynamic deviation from nucleate boiling ratio (DNBR) and local power density (LPD) based upon an algorithm that used control rod position information, projected planar radial peaking factors derived from three-axial excore neutron detectors vs. control rod position, reactor coolant system inlet/outlet temperatures and flow, and pressurizer pressure. As an additional point worth noting: the original design precedes all currently applicable IEC and IEEE standards related to digital I&C systems.
Considering the one observed software failure, the fact that there were eight possible combinations which could lead to the condition, the probability of the triggering event (common cause sensor input failure taken from Appendix E of Ref. 12), and a fault duration of ~2,700 hours yields the following failure on demand probability:
PCCF = 8(PSensor-CCF)x 1.01x10-6/hr x 2,700 hr =8 x 8.4x10-4 x 1.01 x10-6/hr x 2,700 hr = 1.83 x10-5
This single event failure on demand probability would still be within the suggested design reliability objective of <5.0 x 10-4 on demand. The magnitude of this specific failure probability is dominated (>30:1) by the other observed calibration, hardware, and data handling common cause failures. It does raise the question about what if a longer fault duration exposure time had existed and whether such long fault duration times are a unique aspect of hidden software bugs?
Finding bugs
An assertion is frequently made that these hidden latent software errors are a unique weakness of Digital I&C systems – and thus are not found in the older analogue/relay based systems being replaced. In reality, nothing could actually be further from the truth!
Any review of actual reported operating experience shows many vivid examples of complex relay systems designed as safety class 1E controls but which because of their complexity contained latent design errors. Some of these have had fault durations of ten years or more. From personal experience I note the two following examples uncovered during the systems analysis for the Millstone-1 probabilistic risk assessment (PRA) in which the analyst carried the level of system modeling down to the relay contact pair level (which was not common in the PRA studies of the early 1980s). In the course of this he found actual latent design errors which had not been triggered because the specific triggering events had not occurred. This is essentially the same phenomenon as with latent software bugs – and they would be quantified in pretty much the same manner. The events are described below.
Event 1: While performing the PRA study of Millstone 1 (General Electric designed Boiling Water Reactor) an analyst identified a single time-delay relay in the Loss of Normal Power control logic [Ref. 9]. The single actuation relay was designed to initiate load shedding logic to all 4160V breakers to allow onsite emergency generators to start and then begin the process of reloading. If this time delay relay failed to re-close, all 4160V breakers would be blocked from re-closing. The only way to recover would be by removing local control power fuses – an action that would not be easily decided upon by operators or carried out in an emergency situation. This latent single failure design error was discovered after the unit had been operating for about 10 years.
Event 2: Shortly after the above failure was identified, an additional latent design error was identified [Ref. 10, 11] with the loop selection logic on the Low Pressure Coolant Injection (LPCI) logic. This logic included differential pressure sensors to identify high flow through a hypothetical broken recirculation pipe section and then re-direct LPCI flow to the unbroken recirculation loops. The error involved cross-wiring such that LPCI flow would be re-directed to the broken loop instead of the intact loop. Again, the logic was safety class 1E, very complex, and its failure modes not completely recognized until 10 years after the unit started operation.
So, in this regard Digital I&C systems do not have failure modes which are new and unique and not found in older analogue/relay systems. The issue is more that safety reviewers have only been focusing on the undetected latent failure potential of software errors in their reviews of newer digital I&C systems – while ignoring the fact that older I&C systems also contain exactly the same type of undetected latent failures - executed in hardwired logic – and which also are not accounted for in PRA analyses. Sometimes these are found in design reviews – and obviously sometimes they are not found until they are revealed in some operating incident.
Conclusions
A realistic (and achievable) design reliability goal for digital I&C systems used for reactor trip can be generated from existing risk assessment models based upon sensitivity studies. When this was done for a specific class of CE designed reactors using USNRC presumed failure rate data, the required goal emerged as: <5.0x10-4 on demand. While designers and safety reviewers might like to see a lower design objective, it makes no sense to require the I&C logic system to have a failure probability three or more orders of magnitude lower than the best achievable common cause failure probabilities of breakers and control rod jamming probabilities.
Data generated from actual operating experience does exist for digital I&C systems. This data clearly indicates the most dominant sources of common cause failure – and contrary to popular opinion it is not related to latent software bugs. The dominant sources of common cause failure are what have always existed in I&C systems: common cause calibration errors, common cause errors in generating setpoints, and common cause hardware and sensor failures. Until these sources of failure are dramatically reduced by a factor of at least 30, latent software errors will remain relatively minor contributors to the overall failure on demand probability. Thus supplier analyses, which assume the software contribution to failure on demand probability of a digital I&C system is e (negligibly small compared to other sources), are reasonably accurate in making such an assumption.
Finally, the perception that digital I&C systems are susceptible to latent undetected failure modes unlike existing hardwired analogue/relay systems – is just plan wrong. Older hardwired systems have exactly the same kind of failure potential which is dependent on functional complexity, incomplete understanding of actual functional requirements, and insufficient testing and verifications during startup commissioning. In conclusion: properly designed digital I&C systems are reliable enough.
Author Info:
Dr. John H. Bickel, Evergreen Safety & Reliability Technologies, LLC, Evergreen, Colorado, USA 80439, is an independent nuclear engineering consultant with over 34 years professional experience including I&C design, safety analysis, performing and managing nuclear power plant risk assessments, and supporting licensing reviews. He has ten years of experience with a nuclear operating organization and has served as a consultant to the US Nuclear Regulatory Commission (USNRC), and others. The views expressed in this paper are his alone.
Related ArticlesDigital I&C is safe enough - references NRC requests extra information on EPR I&C system Areva says more I&C answers by year end Areva to supply I&C system for Novovoronezh-2FilesTables & Figures